Introduction
SPARQL is a query language currently under design by the Data Access Working Group of the World Wide Web Consortium. It is the first attempt to establish a neutral query language for RDF data, in the hopes of maturing the activities of the "Semantic Web". With a standardized query language, RDF implementations can be changed while maintaining the same client side implementation. As a positive example, SQL was developed as a relational database query language, was accepted by the database community, and serves to ease developer transition between database servers. For more information on SPARQL, see the current W3C working draft.
Sesame is an RDF server implementation, currently one of several. It is known for good web services for persistent RDF information. It communicates using several protocols, including HTTP and SOAP, using several query languages, including SeQRL, RDQL, and RQL, in order to query a stackable backend persistence model, known as SAIL. While perhaps not as simple to use as other RDF servers (Jena, for instance), it is one of the more developed ones and can be more powerful. For more information on Sesame, see the Sesame web site.
This document outlines the design considerations and architecture of an implementation of SPARQL, particularly for Sesame. Other versions of SPARQL include those written for other Java-based servers, such as Jena and Joseki, as well as non-Java versions for non-Java RDF servers. Sesame does not currently have a SPARQL processor. The document is meant for the developer who is either looking to integrate SPARQL into their own Java RDF server or perhaps is looking for design ideas to implement a different query language. While the architecture is certainly not extraordinary or unique, some of the design goals that motivated the architecture are at least a rarity.
The first section will give an overview of the system, including how RDF servers tend to work, and give some high level concepts. Then in the second section, the goals that led to the design choices will be more formally established. The third section is a discussion of how these goals are realized in the design. Finally, the fourth section is a lower level breakdown of the actual architecture, including class diagrams.
System Overview
Server Overview
As mentioned briefly in the introduction, Sesame is somewhat of a middle-layer framework for easing developer and/or end-user access to persistent RDF data. It currently is in the middle of a rewrite, but the main concepts are the same. There are mainly two ways to use the query model API:
- an interface to the RDFStore can be utilized that allows very general matching with wildcards to a particular triple
- the query can be converted into a SAIL query object, which is then executed itself
The first option results in a more language specific implementation, that one can count on to be true to specification. However, it suffers from the inability to optimize the query for the underlying persistence easily and generically, which can be a serious drawback with large queries against SQL databases. The second option is limited by the bounds of the SAIL query language, which while extensive, could not account for all future possibilities.
Jena seems to operate in a very similar manner, offering simple facade methods to match triples as well, or allowing more in-depth implementations of the languages to do their own optimizations.
Language Overview
SPARQL is based, in general, on the Turtle RDF description language. This means it uses header bases and prefixes and uses the n-triples simplistic way of writing RDF descriptions. The language has four separate query types - select,describe,ask,and construct - which are all actual read-only query types, none are writeable updates. They all share dataset shaping statements, such as "graph" (graph binding), "union" (variable binding 'or'), "optional" (variable binding left join), and a triple matching, all intersected. The difference in the queries is how the data is processed after that, to construct the output. The main difference between this language and previous ones is the addition of named graphs, which allow more complex subgraph nesting and queries.
Basic Concept
The basic goal of this project, which is perhaps the most interesting part, is to implement the query language independent of the server implementation. This is NOT traditionally how query languages have been implemented. To again point to the commonly known SQL example, each SQL server implements it's own version of SQL that conforms to the specification. However, this commonly results in implementations that do not conform to specification entirely, as well as duplicating major areas of code and developer time that could be factored out between servers. The main argument against this general approach is that it would be inefficient, because it's not tailored to a particular server. Hopefully, the design of this query language may overcome that complaint somewhat.
Design Goals
Taking into account the goal of a server independent query language implementation and the constraints of the language as well as the general RDF server architecture, the project will have the following design goals:
-
Independence
Should not rely on any code of a particular server implementation, nor on specific ideas of underlying RDF logic, beyond what can be generalized cross-RDF platform.
-
Deployability
Should be able to be easily deployed into a server implementation, without needing to be rebuilt.
-
Correctness
Because of it's potential wide usability, it needs to be very accurate.
-
Flexibility
Should be flexible, since the language is not finalized yet and changes are still happening. This will also make future versions of the language easier to implement.
-
Efficiency
The implementation will not be used if it can not be efficient. It should be able to support platform-specific optimizations.
Strategies
With the aforementioned design goals in mind, several problems seem evident. The main problem, as mentioned earlier, is that the goal of deployability and independence seem to contradict the goal of efficiency. With that in mind and following the example of how RDF servers seem to be designing their own query languages, the design will incorporate a two-pronged approach.
Easy Solution
First, the project will have a generic implementation of the SPARQL specification using a common facade for access to the RDF server data. This interface will allow RDF triple wildcard queries, but no extra logic for dealing with the query as a whole or for joining triple queries. The logic will be implemented as per specification, using this interface. A server will only have to write adapters to their data store and use the included parser to generate the SPARQL query object which will accept the adapters. This is a good option for independent RDF server implementations and quick added functionality.
Efficient Solution
Second, the project will allow for optimizations to the generic logic. This has the penalty of not assuring specification compliance, but will allow those major improvements on efficiency when greater underlying data knowledge is available. To allow this while sticking to the deployability goal, the design falls back on some common design patterns that really define the architecture of the system.
Class structure
There are two main types of interfaces in the system, logic and data. The data interfaces specify the accessor methods that define the structure of a SPARQL query. The parser generates objects that conform to these interfaces. The logic interfaces define the requirements that are needed to evaluate the query in-between different objects in the query object. The appropriate intersections of these interfaces result in the actual interface for a particular part of the query object. The reason for this separation of the data and logic interfaces of the objects is so that the logic can be delegated out.
(At this point, the reader should have an understanding of design patterns. If not, they shouldn't be reading a OO design specification. Go away.)
Delegate Pattern
This is roughly an example of the Chain of Responsibility or Proxy pattern in the GoF definitions. Semantically, it's being used as a dynamic behavior selector, which seems to fit the CoR pattern, but it's never more than a one object chain. From here on, it will be called delegation. So now we have the parser objects that implement both logic and data interfaces, but delegate their logic handling to separate logic objects which implement just the logic.
Abstract Factory Pattern
At this point it seems like superfluous object creation, until you use an abstract factory pattern to control the creation of the logic objects. Then, at creation time, the parser objects can select which logic to use by calling the appropriate factory method. The default abstract factory class returns references to the default SPARQL logic. Implementors that wish to shortcut decisions or use custom implementation code, can override the factory to make the parser objects use that logic. This way, no recompilation of the SPARQL library will be necessary.
Factory Manager
The easiest design would be to use a static factory pattern to manage the particular logic factories. However, using static methods is in general a bad design practice, as it limits flexibility to give convenience. The best design would probably be to pass the factory to the parser for use in object creation. However, the parser is generated automatically by JavaCC and in the interests of flexibility, it's good to keep the grammar file as generic as possible. Therefore, the default logic factory will be hard-coded into the parser objects and the visitor pattern will be used to change the logic of the parser objects at runtime.
Visitor Pattern
The visitor pattern is used in several other ways in the backend of the design. It's used to resolve URIs by prepending prefixes and bases to relative URIs in objects. It's also used to aggregate triple statements from shorthand statements. Objects like collections can be nested indefinitely and each collection generates a bunch of triple statements upon expansion. These all go into the final query.
System Architecture
Package Structure
The design is broken down into ten main packages:
- sparql.model - the intersection of specialized main query object interfaces
- sparql.model.logic - the logic interfaces that are used to evaluate the query object
- sparql.model.data - the data interfaces that are used by the logic to get subobjects and atomic tokens
- sparql.common - holds non-query object related interfaces, such as RdfBindingSet
- sparql.common.impl - the implementations of the non-query object interfaces
- sparql.logic - the main query object default SPARQL logic implementations
- sparql.logic.expression - the default logic implementations for the SPARQL expressions, relational and numeric
- sparql.logic.function - the default logic implementatiosn for the SPARQL function set
- sparql.parser - the implementation of the parser, as generated by JavaCC and JJTree
- sparql.parser.model - the underlying data model that implements the data interfaces and delegates the logic
Package Diagram
From a high level, the basic package diagram looks like this:

Interface Objects (common, common.impl)
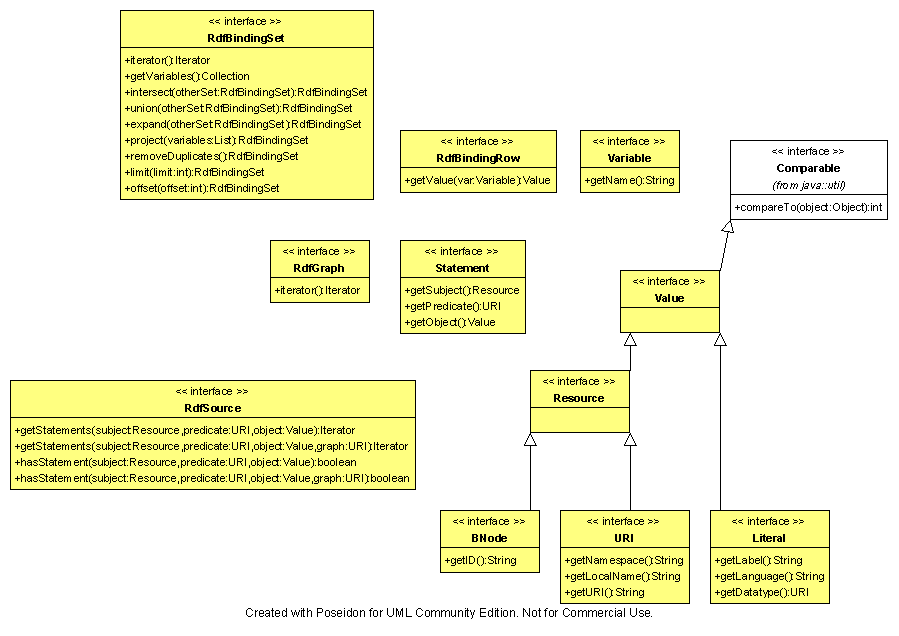
The only objects with which a client interacts during a normal query processing session are those that implement an interface found in sparql.common. These interfaces define the inputs and outputs of the library and are the most semantically defined objects in the library. RdfSource is the standard input to all the query methods, and you will get back a RdfGraph, which is a collection of Statements, or a RdfBindingSet, which is a collection of RdfBindingRows. The values in both of those subinterfaces are one of a URI, BNode, or Literal.
The implementations of the interfaces (not shown) are basic memory implementations, as well as implementing some addition interfaces to make them useful for expression processing in the query.
Query Model (model, model.logic, model.data)
The query model makes up both the interfaces that are used for evaluation, as well as the interfaces that define the accessor methods of the query objects.

The logic model is probably the most important part of the whole library, since it defines the main interfaces for processing the query object. The basic idea is that there are frontend query logics, that then use recursive constraint logics to constrain the graph. The most powerful and general part of the design is the ExpressionLogic interface, which a large majority of the classes in the library implement. It makes use of the recursive nature of expressions to recursively evaluate an expression. Typically the only undefined thing in an expression are variables, which are evaluated using the passed RdfBindingRow. Functions and expressions do runtime checking to assure the correct type of input to the expressions.

There isn't much structure in the data model, since the structure appears in the aggregations of the object model. In general, there is a query object which has nested constraint objects, which contain nested expression objects.
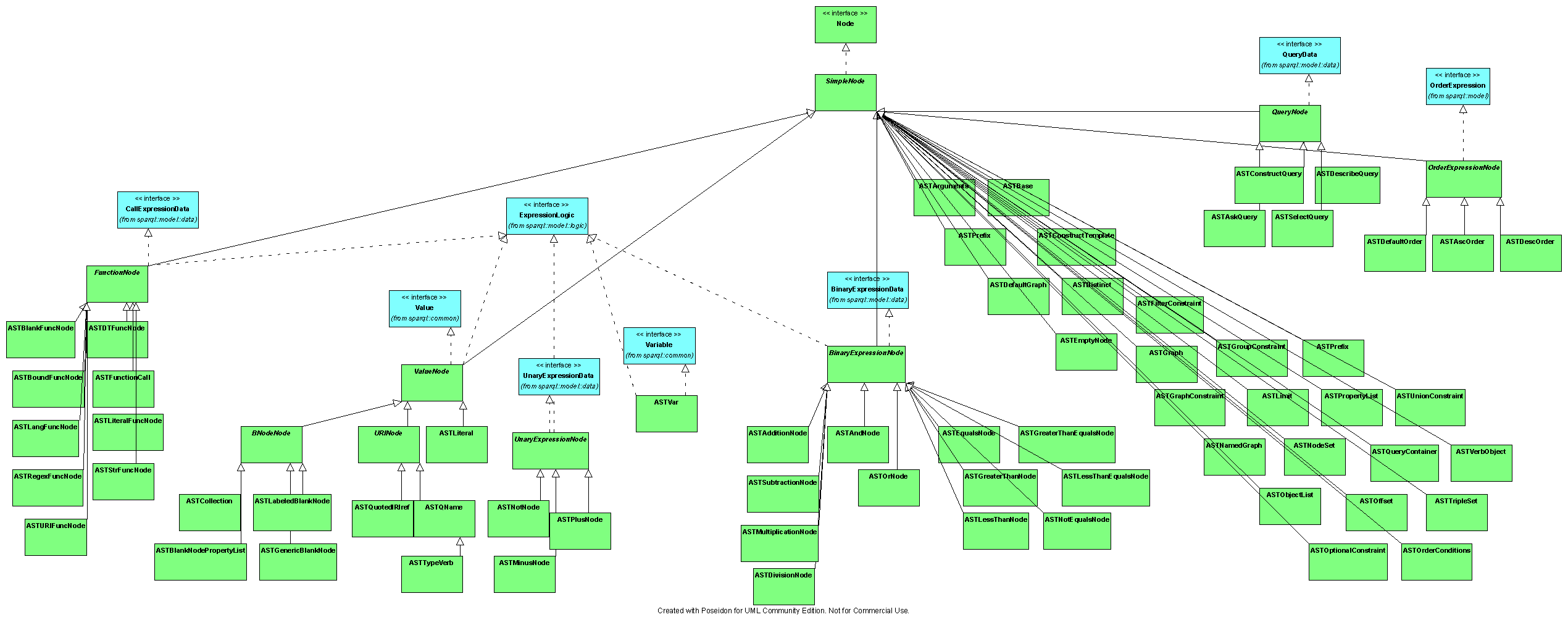
Parser Implementation
See the large parser object model here
{kind=link}
The parser generates a composite of nodes (that implement the Node interface) that are concrete realizations of the data model. To increase flexibility, a lot of these nodes are generated, instead of using more complex object definitions. This limits the amount of code that is necessary in the grammar files and the amount of code that is needed in new class files.
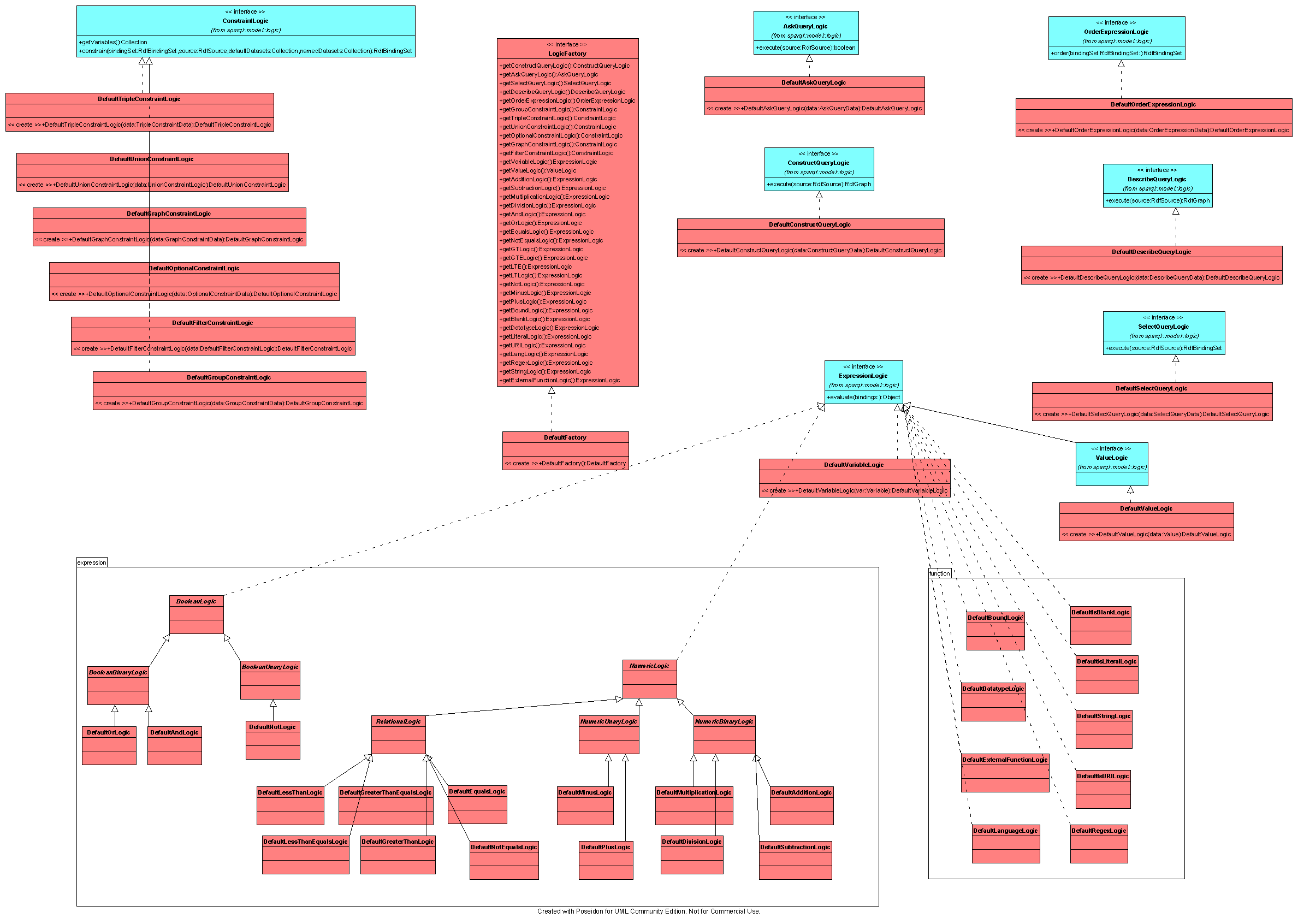
Default Logic
See the large default SPARQL logic here
{kind=link}
The default logic is merely a realization of the logic model for each of the logic units within the grammar. While there is a lot of code in the logic objects, they typically only have one logic method and a constructor which holds the data object to operate on.
Server Deployment
To quickly incorporate the library into a RDF server, it's only necessary to write an adapter class that implements RdfSource and converts the atomic objects in those methods (URI,Value,Resource) into the native types and then converts the returned statements into the correct SPARQL types. Then create an instance of the parser using a desired input stream, get an instance of the Query object from the parser, execute it on the adapted RdfSource, and deal with the resulting binding set or graph.